728x90
반응형
SMALL
1. 글을 작성하게 된 계기
데이터 전처리를 하다 보면 데이터에 문자열 중간중간에 다중 공백이 있는 경우들이 많다.
그래서 해당 공백들을 제거하는 여러 방법과
속도 측면에서 어떤 것이 좋을지에 대해서 정리하고자 한다.
2. 다중 공백 제거하는 방법
방법 1) 문자열을 리스트로 나누고 다시 문자열로 합치기 (split → join)
contents = 'This cafe is a good restaurant.'
text = ' '.join(contents.split())
print(text) # This cafe is a good restaurant.
방법 2) 정규표현식(re) 이용하기
import re
contents = 'This cafe is a good restaurant.'
text = re.sub(' +', ' ', contents)
print(text) # This cafe is a good restaurant.
3. 방법 1과 방법 2 속도 측면 비교
import perfplot # 버전: 0.11.1
import re # 버전: 2.2.1
def setup(n):
str_word = 'happy '
str_content = ''
for _ in range(n):
str_content += str_word
return str_content
def use_re(str_content):
re.sub(' +', ' ', str_content)
def use_split_join(str_content):
' '.join(str_content.split())
# 성능 측정
perfplot.show(
setup=setup,
kernels=[use_split_join, use_re],
n_range=[2**k for k in range(5, 20)],
equality_check=False,
xlabel='number of word')
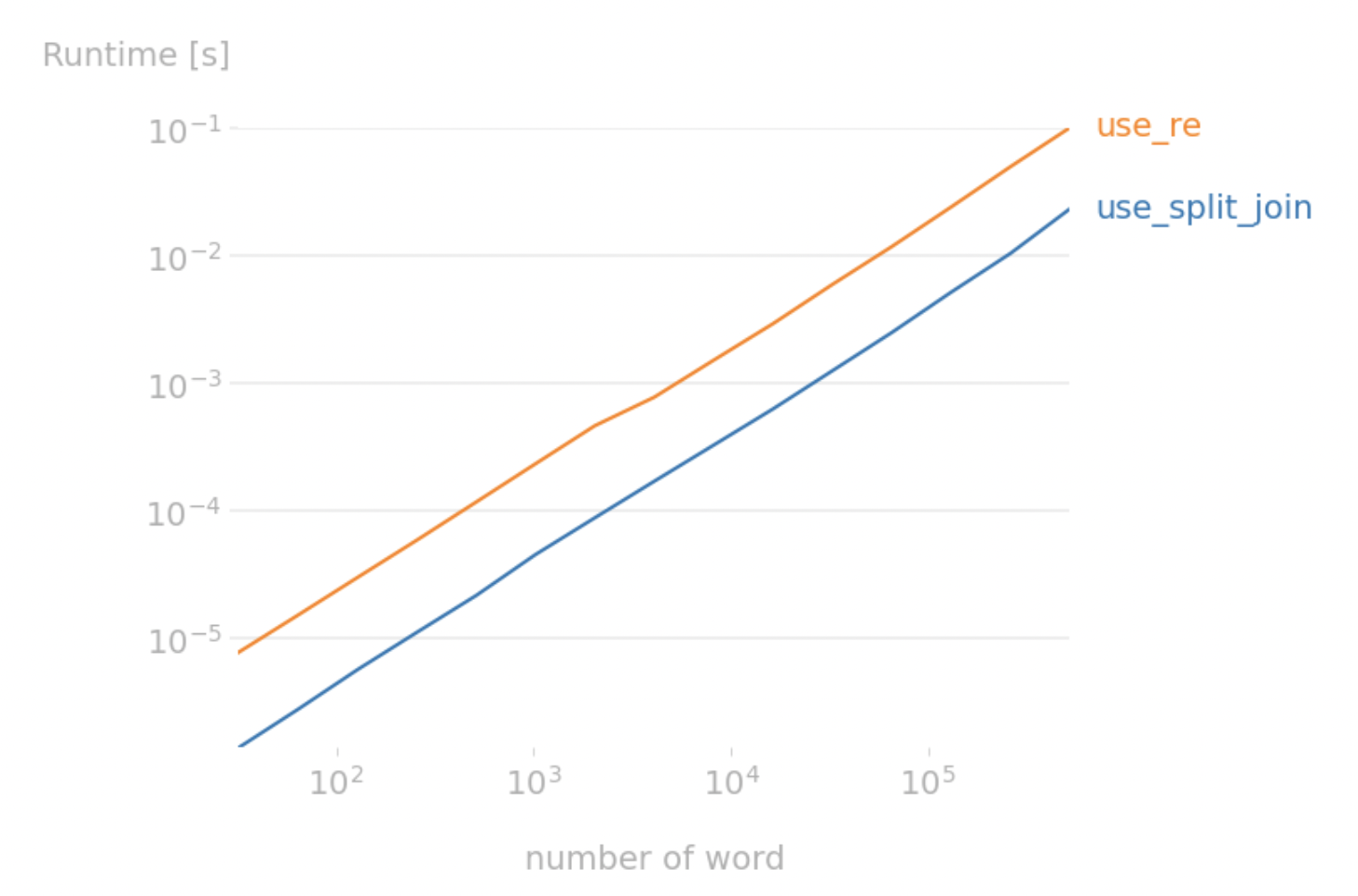
방법 1 (use_split_join) : split, join을 이용한 다중 공백 제거
방법 2(use_re) : 정규식을 이용한 다중 공백 제거
그래프로 보여지는 것처럼 속도 측면에서는 split과 join을 이용한 1번 방법이 더 좋은 것으로 판단됩니다.
728x90
반응형
LIST
'Python > Data Engineering' 카테고리의 다른 글
| DataFrame에서 줄 바꿈, 띄어쓰기 중복 제거 (0) | 2023.02.10 |
|---|---|
| 한국어 문장 분리기 (kss - korean sentence splitter) 사용방법 (0) | 2023.02.10 |
| py-hanspell을 이용한 네이버 맞춤법 검사기 (2) | 2023.01.24 |
| KoNLPy를 활용한 한국어 형태소 분석기 비교 (0) | 2023.01.24 |
| Mecab 설치 에러 해결 : Exception: Install MeCab in order to use it: http://konlpy.org/en/latest/install/ (0) | 2023.01.22 |



