1. 글을 쓰게 된 계기
프로젝트를 진행하면서 한국어에서 유의미한 내용만 전처리하는 과정을 수행하게 되면서
한국어 형태소 분석기가 여러 종류가 있고 그것에 대해서 정리해 보면 좋겠다고 생각하게 되었습니다.
(Okt를 쓰면서 띄어쓰기 유무에 따라 10분 이상 차이 나는 것을 보며 충격 먹었다.)
많은 형태소 분석이 있겠지만 저는
Okt, Komoran, Kkma, Mecab을 비교해보려고 합니다.
2. 사전 작업
okt, komoran, kkma를 사용하기 위해서는 konlpy를 설치만 하면 된다.
mecab을 사용하기 위해서는 bash 창에서 아래 코드처럼 실행해 준다.
(OS별로 다른 설치 코드가 있기 때문에 KoNLPy 사이트를 참고하자)
# okt, komoran, kkma를 사용하기 위한 konlpy 설치
pip install konlpy
# mecab을 사용하기 위한 설치 (Mac os 기준)
bash <(curl -s https://raw.githubusercontent.com/konlpy/konlpy/master/scripts/mecab.sh)
그래도 mecab이 잘 설치가 안되고 다음과 같은 에러가 난다면 여기를 참고해서 해결하자.

3. 각 케이스에 따른 형태소 분석 결과
한글에는 여러 케이스들이 존재하는데 그중에서도 맞춤법과 띄어쓰기 기준으로 경우의 수를 나눠보았습니다.
1. 맞춤법이 잘 지켜지고, 띄어쓰기가 잘 되어 있는 문장
2. 맞춤법이 잘 지켜졌으나, 띄어쓰기가 안 된 문장
3. 맞춤법이 잘 지켜지지 않고, 띄어쓰기가 잘 된 문장
4. 맞춤법이 잘 지켜지지 않고, 띄어쓰기가 안 된 문장
과연 위와 같은 4가지 경우에서 어떤 형태소 분석이 가장 좋은 결과를 보여줄까 궁금해졌습니다.
print('Mecab : ', mec.pos(text, flatten=False, join=True))
print('Komoran : ', kom.pos(text,flatten=False, join=True))
print('Kkma : ', kkm.pos(text,flatten=False, join=True))
print('Okt : ', okt.pos(text,norm=True, stem=True, join=True))(1) 맞춤법이 잘 지켜지고, 띄어쓰기가 잘 되어 있는 문장

분석결과를 보았을 때 어떤 형태소 분석기든 좋은 결과를 보여주고 있습니다.
(2) 맞춤법이 잘 지켜지고, 띄어쓰기가 안 된 문장

제가 테스트한 문장에 대해서는 Kkma가 비교적 자세하게 형태소를 분류하고 있었습니다.
그리고 띄어쓰기가 되어있지 않아도 맞춤법에 문제가 없으면 분석 결과에 대한 걱정은 필요 없는 것을 확인했습니다.
그리고 Okt의 경우에는 다른 분석기들과 다르게 stem과 norm이라는 파라미터가 존재해서 단어들을 알아서 정규화해 주고 오타도 조금은 수정해 주는 기능이 있습니다.
(3) 맞춤법이 잘 지켜지지 않고, 띄어쓰기가 잘 된 문장

맞춤법이 맞춰지지 않자 형태소 분석기가 문제가 생기는 걸 확인할 수 있습니다.
오타가 없는 경우에는 상관없겠지만, 보통의 정제되지 않은 raw data들은 오타가 많은 경우가 있습니다.
그래서 이걸 확인하고 전처리할 때 맞춤법 검사기를 먼저 돌려야 하나,, 하는 생각을 하게 되었습니다.
(4) 맞춤법이 잘 지켜지지 않고, 띄어쓰기가 안 된 문장

맞춤법뿐만 아니라 띄어쓰기까지 안되어 있으면 제대로 형태소 분석을 아예 못하고 있는 모습을 보이고 있습니다.
물론 단편적인 한 문장으로만 확인한 것이기 때문에 더 사용해 봐야겠지만,
한글 텍스트를 분석할 때 전처리를 어떻게 해야 할 지에 대한 고민을 하게 되는 부분이었습니다.
4. 분석기별 소요시간 비교
import time
from tqdm import tqdm
import matplotlib.pyplot as plt
import seaborn as sns
def tagger_time(tagger, texts):
time_sum = 0
for sentence in tqdm(texts):
time_1 = time.time()
try:
tagger.morphs(sentence)
except:
pass
time_2 = time.time()
time_sum += (time_2 - time_1)
return time_sum
texts = df_all.caption[:1000]
time_list = []
for tagger in [kkm, kom, okt, mec]:
time_list.append(tagger_time(tagger, texts))
sns.set_style('whitegrid')
tagger = ['Kkma', 'Komoran', 'Okt', 'Mecab']
plt.figure(figsize=(10,8))
plt.bar(tagger, time_list, color=(0.4,0.7,0.5))
plt.title('Learning Time for 1000 reviews', fontsize=17)
plt.xticks(fontsize=14)
plt.ylabel('total seconds')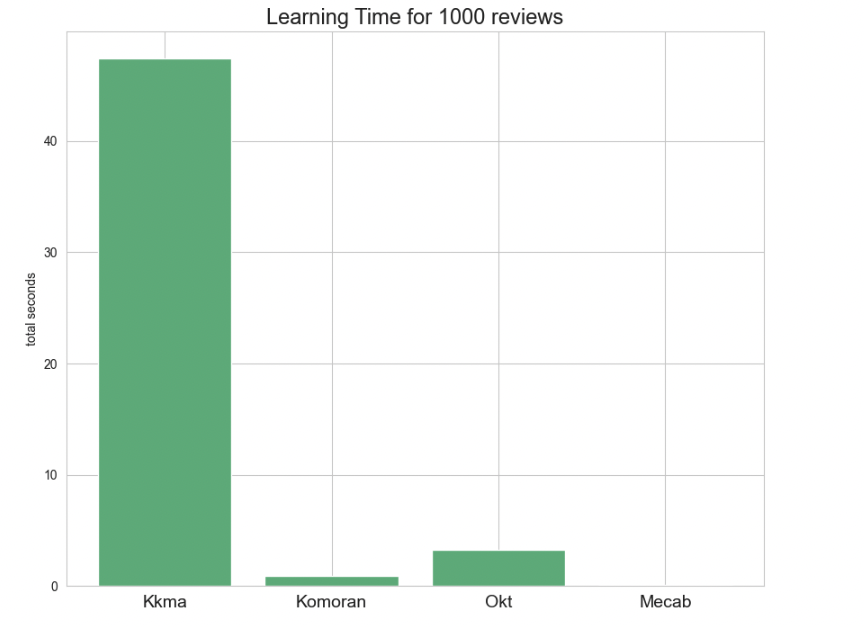
1000개의 ★그램 게시글 데이터로 분석기 소요시간을 확인해 본 결과
Kkma > Okt > komoran > Mecab 순으로 Kkma가 가장 오랜 시간이 걸렸고 Mecab이 가장 빨랐습니다.
5. 결론 + 느낀점
저런 모델을 만들기 위해서 얼마나 많은 데이터들을 수집하고 정제하고 학습하는 과정을 거쳤을까라는 생각이 든다.
한국어를 처리할 수 있도록 만들어진 여러 분류기 모델일 있어서 너무 감사하다는 생각을 했다.
구글링 하면서 느낀 것은 새로운 자연어 처리 분류기들이 만들어지고 있었고
각 분석기별로 장단점이 있으며, 각 데이터와 상황에 맞는 분류기를 써야 한다는 것을 느꼈다.
이 글을 읽으시는 분도 제 글을 참고해서 상황에 맞는 분류기를 사용해 보면 좋을 것 같습니다!
'Python > Data Engineering' 카테고리의 다른 글
| 한국어 문장 분리기 (kss - korean sentence splitter) 사용방법 (0) | 2023.02.10 |
|---|---|
| 문자열 중간 다중 공백 제거하는 방법 (0) | 2023.01.28 |
| py-hanspell을 이용한 네이버 맞춤법 검사기 (2) | 2023.01.24 |
| Mecab 설치 에러 해결 : Exception: Install MeCab in order to use it: http://konlpy.org/en/latest/install/ (0) | 2023.01.22 |
| 정규식을 이용한 데이터 전처리(문자만 남기기) (0) | 2023.01.14 |



