

좋은 그림 캡션들은 논문 독자에게 복잡한 과학적인 그림을 이해하는데 도움을 줍니다. 그러나, 출판된 논문 조차도 종종 부실하게 작성된 캡션을 포함하고 있습니다. 자동 캡션 생성은 논문 작성자가 더 나은 품질의 캡션을 위해 수정할 수 있는 좋은 출발점을 제공함으로써 도움을 줄 수 있습니다. 이전 연구에서는 그림 캡션 생성을 vision-to-language 과제로 다루었습니다. 이 논문에서는 그림 캡션 생성을 과학 문서에서 텍스트 요약 작업으로 더 효과적으로 처리할 수 있음을 보여줍니다. 우리는 사전 학습된 abstractive 요약 모델인 PEGASUS를 fun-tuning하여 그림을 참조하는 문단(예: "그림 3은...")을 그림 캡션으로 요약하도록 하였습니다. 대규모 arXiv 그림에 대한 실험은 우리의 방법이 자동 및 인가평가 모두에서 이전의 비전 방법을 능가함을 보여줍니다. 우리는 또한 두 가지 주요 도전에 초엄을 맞춘 심층조사를 수행했습니다: (i) 저자가 작성한 낮은 품질의 캡션의 일반적인 존재와 (ii) 좋은 캡션에 대한 명확한 기족의 부족. 우리의 코드와 데이터는 다음에서 확인할 수 있습니다: https://github.com/Crowd-AI-Lab/Generating-Figure-Captions-as-a-Text-Summarization-Task
1. Introduction
- 효과적인 그림 캡션은 독자가 복잡한 그림을 이해하는 데 도움을 주지만, 많은 출판된 논문에서는 부실하게 작성된 캡션이 많습니다. 분석에 따르면, arXiv cs.CL 논문의 선형 차트 캡션 중 약 53.88%가 NLP 독자에게 도움이 되지 않습니다. 자동 캡션 생성은 이러한 문제를 해결하고 더 나은 품질의 캡션을 작성하는 데 도움을 줄 수 있습니다.
- 이전 연구는 일반적으로 그림 캡션 생성을 비전-투-언어 과제로 접근했습니다. 예를 들어, Hsu 등(2021)은 CNN+RNN 구조를 사용하여 이미지를 캡션 텍스트로 변환하는 종단간 접근 방식을 사용했고, Qian 등(2021)은 이미지를 이해하고 주요 정보를 추출하여 템플릿을 사용해 캡션을 생성했습니다. 그러나 이러한 접근 방식은 합성 데이터에서 성공을 거두었지만, 실제 세계의 그림을 캡션하는 데 어려움을 겪었습니다. 예를 들어, Hsu 등(2021)의 방식은 arXiv 그림을 사용하여 BLEU-4 점수 2.91을 기록했습니다.
- 본 논문에서는 그림 캡션 생성을 텍스트 요약 작업으로 접근할 수 있다고 주장합니다. 그림을 언급하는 문단을 요약하여 캡션을 생성하는 방식입니다. arXiv 데이터 분석에 따르면, 그림 캡션의 75% 이상의 단어가 해당 그림을 언급하는 문단의 단어와 일치하며, 이는 우리의 접근 방식을 지지합니다. 자동 평가 결과, 그림을 언급하는 문단을 요약하는 방식이 이전의 비전 기반 방법보다 더 나은 캡션을 생성하는 것으로 나타났습니다. 외부 도메인 전문가에 의한 인간 평가에서, 우리의 최고 성능 모델의 캡션은 원래 캡션보다 46.67% 더 선호되었습니다.
- 우리는 저자가 작성한 낮은 품질의 캡션의 일반적인 존재와 좋은 캡션에 대한 명확한 기준의 부족이라는 두 가지 주요 도전에 초점을 맞춘 심층 조사를 수행했습니다. 놀랍게도, 샘플에서 저자가 작성한 캡션의 53.88%가 도움이 되지 않는 것으로 판명되었습니다. 이는 향후 캡션 시스템 설계에 영향을 미치며, 데이터 품질이 캡션 성능에 미치는 영향을 강조합니다.
2. Related Work
- 이전의 그림 캡션 생성 작업은 크게 두 가지 접근 방식으로 나뉩니다: (i) 그림의 이미지를 기반으로 한 캡션 생성과 (ii) 그림의 데이터 차트를 기반으로 한 캡션 생성입니다. 초기 이미지 기반 접근 방식은 이미지 이해를 자동화하는 데 중점을 두었으며, 이는 이미지를 해석하여 주요 속성을 추출하고, 이를 미리 정의된 템플릿을 사용하여 캡션으로 변환하는 것이었습니다. 최근에는 딥러닝의 발전으로 이미지의 신경 표현을 사용하여 캡션을 생성하는 종단간 방식이 많이 채택되고 있습니다. 우리의 연구는 비주얼 대신 텍스트에 중점을 두고 캡션을 생성하는 점에서 이전 연구와 차별화됩니다.
- 기존의 그림-캡션 데이터셋은 일반적으로 그림의 동반 문서를 명시적으로 포함하지 않으며, 대부분 이 작업을 비전 과제로 접근했습니다. 최근에는 문서의 텍스트 데이터를 사용하는 지식 증강 이미지 캡션 생성 방법이 도입되어 문서 텍스트 사용의 가능성을 제시하고 있습니다. 일부 접근 방식은 그림의 이미지를 사용하기보다는 그림의 기본적인 표 형식 데이터를 사용하여 캡션을 생성합니다. 초기 접근 방식은 규칙 기반 기술을 사용했지만, 최신 접근 방식은 학습 기반 방법을 선호합니다. 이러한 접근 방식은 표 형식 데이터와 메타 데이터를 활용할 수 있지만, 그림의 원시 데이터에 접근할 필요가 있습니다. 반면, 우리의 연구는 과학 문서의 풍부한 텍스트 정보를 사용하여 캡션을 생성합니다.
3. Problem Statement and Terminology
- 문서 D는 저자가 작성한 캡션 Ci를 가진 n개의 그림 F1부터 Fn까지 포함합니다. 문서 D에서, j개의 문장 Mi,1부터 Mi,j는 Fi를 명시적으로 언급합니다(예: "Fi에 나타난 대로..."). 이 작업의 목표는 Fi를 명시적으로 언급한 문장(Mi,1부터 Mi,j)과 문서 D의 주변 텍스트만을 사용하여 그림 Fi에 대한 고품질의 캡션 C'i를 자동으로 생성하는 것입니다.
- "Mention"은 문서에서 대상 그림을 명시적으로 언급하는 문장을 의미합니다(예: "그림 6에 나타난 대로..."). 여러 Mention이 있을 경우, 첫 번째 Mention을 참조합니다.
- "Paragraph"는 Mention을 포함하는 텍스트의 섹션을 의미합니다. 이 작업에서는 PDF 파싱에 의해 생성된 <p> 태그를 기준으로 Paragraph의 경계를 결정합니다.
- Mention 근처의 문장은 관련 정보를 포함할 수 있으므로, n개의 앞 문장과 m개의 뒤 문장을 추출하여 "Window[n, m]" 텍스트 스니펫을 형성합니다. 예를 들어, "Window[1, 2]"는 하나의 앞 문장, Mention 문장, 두 개의 뒤 문장을 포함하는 네 문장의 스니펫을 의미합니다.
- "OCR"은 광학 문자 인식(OCR) 소프트웨어에 의해 이미지에서 추출된 텍스트 정보(예: 레전드, 라벨 등)를 의미합니다.

열 구성:
- Random: 임의로 선택된 문장 또는 문단.
- Mention: 대상 그림을 명시적으로 언급하는 문장.
- Paragraph: Mention이 포함된 문단.
- OCR: 그림에서 추출한 텍스트 정보.
- Window[n, m]: Mention 문장 주변의 n개의 앞 문장과 m개의 뒤 문장을 포함한 텍스트 스니펫.
행 구성:
- Caption: 캡션의 단어가 소스 텍스트(문장 또는 문단)에서 발견될 수 있는 백분율.
- Source: 소스 텍스트(문장 또는 문단)의 단어가 캡션에서 발견될 수 있는 백분율.
주요 결과:
- 캡션의 단어 중 76.68%가 Paragraph+OCR에서 발견될 수 있으며, 이는 텍스트 요약을 통해 캡션을 생성하는 동기를 제공합니다.
- Mention, Paragraph, OCR 등 다양한 소스 텍스트 조합에서 캡션과의 단어 겹침 비율을 보여줍니다.
- Window[n, m] 텍스트 스니펫을 사용한 경우, 앞뒤 문장을 포함한 문맥 정보가 캡션 생성에 유용할 수 있음을 나타냅니다.
세부 내용:
- Random: 캡션에서 임의로 선택된 문장(S)이 35.23%, 문단(P)이 44.43%의 커버리지를 보입니다.
- Mention: 그림을 명시적으로 언급하는 문장에서는 캡션 단어의 53.43%가 발견됩니다.
- Paragraph: 문단 단위로 보면 캡션 단어의 75.19%가 발견되며, OCR 정보를 추가하면 76.68%로 증가합니다.
- OCR: 단독으로 사용된 OCR의 경우 34.75%의 커버리지를 보입니다.
- Window: 다양한 Window 구성에서 캡션과 소스 간의 단어 겹침 비율을 나타냅니다. 예를 들어, Window[1, 1]의 경우, 앞뒤 문장과 함께 사용하면 65.20%의 커버리지를 보이며, OCR을 추가하면 68.73%로 증가합니다.
요약:
이 표는 캡션과 관련된 텍스트 간의 단어 겹침 정도를 보여줍니다. 특히, 문단과 OCR 정보를 결합하면 캡션 단어의 대부분을 커버할 수 있음을 나타내어, 텍스트 요약을 통한 캡션 생성 방법의 유용성을 강조합니다.
4. Dataset
- 데이터셋 설명: 우리의 연구는 SCICAP이라는 과학 그림 캡션 데이터셋에 기반하고 있습니다. SCICAP은 290,000편 이상의 arXiv 논문에서 추출한 416,000개 이상의 선형 차트와 캡션을 포함하고 있으며, 이는 실세계 과학 그림을 기반으로 한 최초의 대규모 그림 캡션 데이터셋 중 하나입니다.
- 전처리 단계: SCICAP 데이터셋은 그림을 언급하는 문단을 포함하지 않으므로, 원본 arXiv 논문의 PDF 파일을 다운로드하여 모든 언급(Mentions)과 문단(Paragraphs)을 추출했습니다. 데이터셋 재분할 및 OCR 추출을 포함한 상세한 전처리 정보는 부록 B에 설명되어 있습니다.
5. Motivating Analysis
- 분석 목표: 그림을 언급하는 문장과 캡션 간의 상관관계를 이해하기 위해 일련의 분석을 수행했습니다. 특히, 그림 캡션의 단어가 해당 그림을 언급하는 문단에서 얼마나 나타나는지를 조사했습니다.
- 방법론: awesome-align(Dou와 Neubig, 2021)을 사용하여 소스 텍스트(언급, 문단, OCR)와 캡션 간의 정렬을 얻었습니다. SciBERT(Beltagy 등, 2019)를 사용하여 단어의 맥락적 임베딩을 얻고, softmax 임계값 0.99를 사용하여 잘못된 정렬을 줄였습니다.
- 결과: 정렬을 얻은 후, 캡션 정보의 몇 퍼센트가 소스 텍스트에서 발견될 수 있는지를 계산했습니다. 표 1의 결과는 캡션 정보의 76.68%가 문단과 OCR에서 발견될 수 있음을 보여주며, 이는 문단 요약을 통해 그림 캡션을 생성할 동기를 제공합니다. 또한, 동일한 논문에서 임의로 선택된 문장과 문단이 각각 35.23%와 44.43%의 캡션을 커버할 수 있음을 발견하여, 논문 전체에서 일부 일반적인 정보 공유가 있음을 나타냅니다. 정확한 겹침(BLEU 점수)을 사용한 연구는 부록 A에 설명되어 있습니다.
6. Generating Figure Captions as a Text Summarization Task
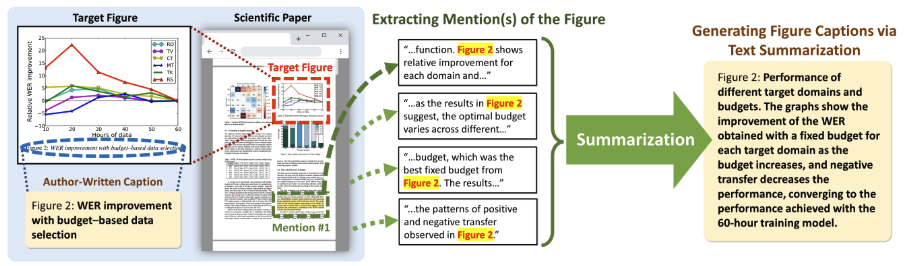
Figure 1은 제안된 파이프라인을 개요로 보여줍니다. 이 섹션에서는 파이프라인의 각 단계를 설명합니다.
6.1. Extracting Mentions and Paragraphs
- Mentions 및 문단 추출: 시스템은 먼저 언급(Mentions)과 관련 문단(Paragraphs)을 추출합니다. 이 논문에서는 Grobid(kermitt2, 2022)라는 도구를 사용하여 PDF 파일을 구조화된 XML 문서로 변환하고, 각 논문의 문단(<p> 태그 포함)에서 일반 텍스트를 추출했습니다.
- 문장 세분화 및 식별: 추출된 일반 텍스트는 BlingFire(microsoft, 2022)를 사용하여 문장으로 분할되었습니다. 특정 그림을 언급하는 문장을 식별하기 위해 정규 표현식을 개발했습니다. 예를 들어, "그림 6에 나타난 대로, ..."와 같은 문장은 먼저 식별된 후 그림 6과 연결되었습니다.
- 정규 표현식 평가: 정규 표현식의 성능을 평가하기 위해 실험 데이터셋에서 300개의 샘플에 대한 수동 평가를 실시했습니다. 결과는 높은 수준의 정밀도(99.58%)와 재현율(94.44%)을 보여주었습니다.
6.2. Generating Captions Using Text Summarization Models
- 캡션 요약: 그림 1에서 보이는 것처럼, 시스템은 추출된 모든 언급(Mentions) 또는 문단(Paragraphs)을 자동으로 요약하여 그림 캡션을 생성합니다. 이 작업에서는 PEGASUS(Zhang et al., 2020)라는 추상적 요약 모델을 사용하여 데이터셋에 맞게 미세 조정했습니다.
- 모델 구성 및 훈련: 다섯 가지 입력 조합을 이용해 다섯 가지 Pegasus 모델(PegasusM, PegasusP, PegasusO, PegasusM+O, PegasusP+O)을 훈련시켰습니다. 이 조합은 (i) Mention, (ii) Paragraph, (iii) 타겟 그림 이미지의 OCR 출력, (iv) Mention+OCR, (v) Paragraph+OCR을 포함합니다. PegasusP+O는 문서에서 가장 많은 관련 정보를 포함하여 최적의 요약을 생성할 것으로 기대됩니다.
- 특화된 모델: 우리는 더 높은 품질의 캡션으로 훈련된 특화된 버전인 PegasusP+O+B도 구축했습니다. 이 모델은 Paragraph+OCR-Better라는 입력 조합을 사용합니다. 신뢰할 수 있는 자동화된 캡션 품질 평가 방법이 없기 때문에, 이전 연구의 가이드라인을 따라 더 긴 캡션이 독자의 이해를 높인다는 점을 고려했습니다(Hartley, 2003; Gelman et al., 2002). 평균 캡션 길이가 26.8 토큰이었으므로 30 토큰을 임계값으로 설정하여 훈련을 진행했습니다. 훈련은 Paragraph+OCR 입력을 사용하여 수행되었습니다.
- 주요 도전 과제: 실세계 시나리오에서 과학적 그림의 캡션을 생성하는 데 두 가지 주요 도전 과제를 확인했습니다. 이러한 도전 과제는 다음 하위 섹션에서 논의되며, 섹션 8에서 심층 분석됩니다.
6.2.1 Challenge 1: Addressing Unreliable Quality of Real-World Data
- 저품질 캡션 문제: 학술 기사에서는 저품질 캡션이 자주 발생합니다. 우리의 분석(섹션 8.1 참조)에 따르면, arXiv cs.CL 논문에서 선형 차트의 저자가 작성한 캡션 중 50%가 도메인 전문가에 의해 도움이 되지 않는다고 평가되었습니다. 이러한 신뢰할 수 없는 데이터 품질의 영향으로 인해, 개발자는 유용하지 않은 캡션으로 캡션 생성 모델을 학습 및 테스트할 수 있습니다.
- 대처 방법: 캡션 품질을 자동으로 평가하는 방법이 없기 때문에 적절한 학습 예제를 식별하고 저품질 예제를 제거하기가 어렵습니다. 이 문제를 해결하기 위해, 우리는 문헌에서 독자에게 더 도움이 된다고 제안된 긴 캡션으로 훈련된 PegasusP+O+B 모델을 포함했습니다(Hartley, 2003; Gelman et al., 2002). 저품질 테스트 데이터를 고려하여, 우리는 인간과 자동 평가를 모두 수행했습니다. 그림 캡션의 데이터 품질 분석은 섹션 8.2에 제시되어 있습니다.
6.2.2 Challenge 2: Defining a Clear Standard for “Good” Figure Captions
- 명확한 기준의 부족 문제: 그림 캡션의 유용성을 판단하기 위한 명확하고 실행 가능한 기준의 부족이 근본적인 문제입니다. 효과적인 과학 그림 캡션 작성에 대한 지침은 있지만(Rougier et al., 2014; Biegel and Kamat, 2019), 이를 알고리즘 모델로 변환하는 것은 어려울 수 있습니다.
- 모델링 관점의 도전 과제: 명확한 목표의 부족은 모델링 관점에서 도전 과제를 제시합니다. 유창성이 확보된 후 무엇을 최적화해야 할지 불확실하기 때문입니다. 이 논문에서는 텍스트 요약을 통해 캡션을 생성하는 가능성을 입증하는 데 중점을 두었습니다. 비록 모델에 특화된 목표를 포함하지 않았지만, 섹션 8.2에서 "좋은" 캡션의 기준을 조사합니다.
7. Experimental Results
- A Simple Baseline: Using Extracted Mentions as Captions: 정보 겹침 연구(섹션 5)에 기반하여, 입력 텍스트의 일부를 예측으로 재사용하는 Reuse 기준선을 만들었습니다.
- Vision-to-Language Baselines: 비전-투-언어 생성은 이 작업을 이미지 캡션 생성 작업으로 처리하여 과학 그림 이미지를 입력으로 받아 이를 설명하는 텍스트를 생성합니다. 두 가지 비전-투-언어 모델을 기준선으로 비교했습니다. 첫째, BEiT(Bao et al., 2022)와 GPT-2(Radford et al., 2019)를 결합하여 시퀀스-투-시퀀스 모델을 구축했습니다. 또한, OCR 작업을 위해 사전 훈련된 트랜스포머 기반 시퀀스-투-시퀀스 모델인 TrOCR(Li et al., 2021) 모델을 선택했습니다. 사진으로 훈련된 ViT(Dosovitskiy et al., 2021) 및 BEiT(Bao et al., 2022)와 같은 이미지 인코더와 비교하여, 인쇄물 및 손글씨 문서로 훈련된 OCR 모델은 과학 논문 도메인과 더 밀접하게 일치합니다. 언급이 필요 없기 때문에 SCICAP의 모든 그림(106,391개의 학습 샘플)을 훈련에 사용했습니다.
- Experimental Setup: 비교를 위해 총 14가지 방법이 포함되었습니다: 여섯 가지 입력 변형(M, P, W[0, 1], W[0, 2], W[1, 1], W[2, 2])을 사용한 여섯 가지 재사용 기준선, 다섯 가지 입력(M, M+O, P, P+O, O)을 사용한 다섯 가지 텍스트 요약 모델, 데이터 품질을 통제한 P+O를 사용하는 한 가지 텍스트 요약 모델, 두 가지 비전-투-언어 모델(BEiT+GPT-2와 TrOCR). 입력 특징을 나타내기 위해 M, P, W, O, B의 아래 첨자를 사용했습니다: 언급(Mention), 문단(Paragraph), 윈도우(Window), OCR, 더 나은 데이터 품질(Better data quality). 모델 훈련 세부 사항 및 디코딩 구성은 부록 C에 제공되어 있습니다.
7.1 Automatic Evaluation Results
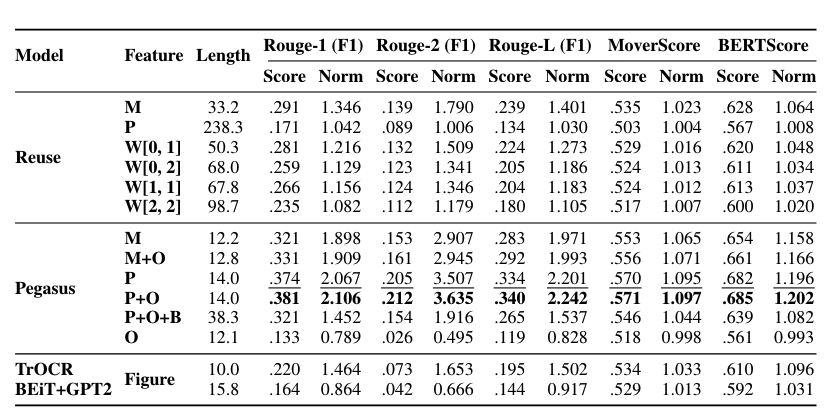
- 기존의 자동 평가 방법: 자동 평가를 위해 ROUGE-1, ROUGE-2, ROUGE-L (Lin, 2004; Nallapati et al., 2016), MoverScore (Zhao et al., 2019), BERTScore를 사용했습니다. ROUGE 점수를 계산할 때는 모든 텍스트를 소문자로 변환하고 어간을 추출했습니다. MoverScore와 BERTScore는 의미적 유사성을 기반으로 하므로, SciBERT (Beltagy et al., 2019)에서 맥락 임베딩을 얻었습니다.
- 캡션 길이에 따른 자동 평가의 정규화: ROUGE F1은 특정 길이 내에서 더 긴 텍스트를 선호하여, 더 긴 텍스트를 생성하는 모델이 더 높은 점수를 받는 왜곡된 비교를 초래합니다(Sun et al., 2019). 이에 따라 우리는 Sun et al. (2019)의 접근 방식을 따라 동일한 길이의 텍스트를 생성하는 랜덤 기준선으로 점수를 정규화했습니다. 이는 랜덤 기준선(Random(length))과 생성된 텍스트의 길이를 사용하여 정규화된 점수(Scorenormalized)를 계산하는 방식입니다. 랜덤 기준선 점수는 여러 (길이, 랜덤 점수) 쌍에 대해 선형 보간법을 적용하여 추정했습니다. 각 길이 설정에서 10개의 다른 랜덤 시드를 실행하여 평균을 보고했습니다.
- 정규화된 자동 평가 결과: 표 2는 정규화된 자동 평가 결과를 보여줍니다. 전반적으로, 모든 정보를 사용한 텍스트 요약 모델인 PegasusP+O (Paragraph+OCR)가 세 가지 모든 지표에서 최고의 성능을 달성했습니다. 동일한 정보를 사용했지만 더 나은 캡션 집합으로 훈련된 PegasusP+O+B (Paragraph+OCR-Better)는 좋은 성과를 내지 못했습니다. 이는 테스트 데이터의 절반이 저품질 캡션으로 구성된 것에 기인한다고 가정했습니다(섹션 8.2 참조). 이는 다양한 품질 빔에서의 성능 변화를 검토하고(섹션 8.1), 인간 평가(섹션 7.2)를 수행하여 검증했습니다. 한편, Mention을 사용하는 Reuse 기준선인 ReuseM은 다른 Reuse 기준선을 능가했습니다. 그러나 문맥 크기가 커짐에 따라 성능이 감소했습니다.
7.2 Human Evaluation Results
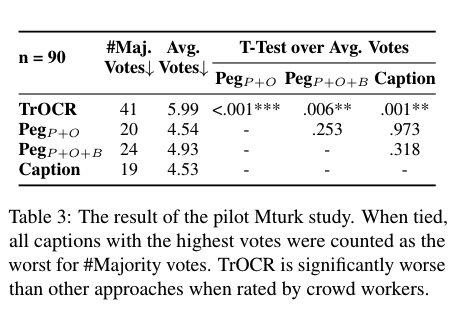
- Pilot MTurk 연구를 통한 상위 모델 선택: 주요 인간 평가 전에, Amazon Mechanical Turk(MTurk)에서 파일럿 연구를 수행하여 최종 연구에서 성능이 저조한 기준선을 제외하고 주요 인간 평가를 단순화했습니다. 이 연구에서 MTurk 작업자들에게 그림을 주의 깊게 읽고 (i) TrOCR, (ii) PegasusP+O, (iii) PegasusP+O+B, (iv) 실제 캡션 중 가장 나쁜 캡션을 선택하도록 요청했습니다. 오류가 없는 90개의 그림을 무작위로 샘플링했으며, 각 그림에 대해 20명의 MTurk 작업자가 평가를 내렸습니다. 결과는 TrOCR의 캡션이 90개 중 41번 다수 투표를 받았고, 평균 투표 수가 다른 것보다 현저히 높았습니다. 따라서 TrOCR을 공식 인간 평가에서 제외했습니다.
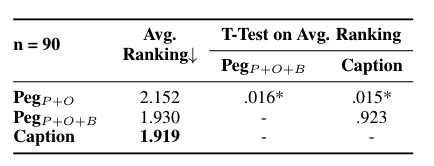
- 도메인 전문가와 함께한 주요 인간 평가: NLP 배경을 가진 세 명의 박사 과정 학생들을 인간 평가자로 모집하여 캡션을 평가하게 했습니다. 파일럿 MTurk 연구에서 사용된 동일한 90개의 그림을 다시 사용하여 (i) PegasusP+O, (ii) PegasusP+O+B, (iii) 실제 캡션을 비교하도록 했습니다. 평가자들은 "이 캡션이 그림이 전달하려는 메시지를 이해하는 데 도움이 된다"고 얼마나 강하게 동의하는지를 기준으로 캡션을 순위 매기도록 요청받았습니다.
- 평가 결과: 평균 순위는 실제 캡션과 PegasusP+O+B가 유사하게 평가되었습니다(1.919 대 1.930, p-value = 0.923). 평가자들은 PegasusP+O보다 PegasusP+O+B를 더 선호했습니다(1.919 대 2.152, p-value = 0.016). 이는 캡션 길이에 기반하여 품질을 자동으로 결정하는 우리의 휴리스틱을 지지하며, 더 긴 캡션이 독자의 이해를 돕는다는 이전 연구 결과와 일치합니다. 그러나 평가자 간의 낮은 상관관계(Kendall’s tau 값 0.133, 0.148, 0.274, Spearman’s rho 값 0.128, 0.156, 0.317)는 이 작업의 복잡성을 강조하며, 도메인 간 인간 평가를 확장하는 것이 어려울 수 있음을 시사합니다. 캡션 길이와 같은 다양한 선호도는 평가자 간의 일치도를 낮출 수 있습니다.
8. In-Depth Analysis
- 주요 도전 과제: 우리는 두 가지 주요 도전 과제에 초점을 맞춘 심층 조사를 수행했습니다: (i) 저자가 작성한 저품질 캡션의 일반적인 존재와 (ii) 좋은 캡션에 대한 명확한 기준의 부족.
- 품질 주석 절차: 테스트 세트에서 계산 및 언어 분야(cs.CL)의 438개 캡션을 수동으로 주석 처리했습니다. 그림 6(부록 D 참조)에는 우리가 사용한 인터페이스가 나와 있으며, 여기에는 논문의 제목, 초록, PDF 파일이 대상 그림의 이미지, 캡션, 질문과 함께 표시되었습니다. 각 캡션에 대해 주석자(공저자)들에게 다섯 점 리커트 척도를 사용하여 네 가지 측면을 평가하도록 요청했습니다:
- 이미지-텍스트: 캡션에 그림의 명명된 개체 또는 중요한 단어/숫자(예: 제목, 범례, 라벨 등)가 포함되어 있는지.
- 시각적 설명: 캡션에 그림의 시각적 특성(예: 색상, 모양, 추세 등)이 포함되어 있는지.
- 핵심 메시지: 캡션에 그림이 전달하려는 고수준의 핵심 메시지 또는 결론이 명시되어 있는지.
- 도움 여부: "캡션이 그림이 전달하려는 메시지를 이해하는 데 도움이 되었다."
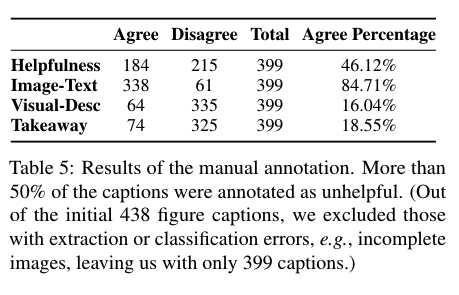
- 주석 데이터 통합: "매우 동의"와 "동의"를 "[동의]"로, "중립", "반대", "매우 반대"를 "[반대]"로 그룹화하여 주석 데이터를 통합했습니다. 이 통합 결과는 표 5에 제시되어 있습니다.
8.1 Challenge 1: Addressing Unreliable Quality of Real-World Data

- 저품질 캡션 문제: 표 5에 따르면, arXiv cs.CL 논문에서 저자가 작성한 캡션 중 50% 이상이 도움이 되지 않는 것으로 평가되었습니다. 높은 비율의 저품질 캡션은 생성된 텍스트를 인간이 작성한 캡션과 비교하는 자동 평가 결과를 왜곡할 수 있습니다. 이를 해결하기 위해, 우리는 표 5에 제시된 399개의 주석이 달린 그림 캡션을 사용하여 다양한 품질 빔으로 모델을 평가했습니다. 캡션은 "도움이 되는 빔"(184개의 [동의]로 평가된 캡션)과 "도움이 되지 않는 빔"(215개의 [반대]로 평가된 캡션)으로 나누어졌습니다.
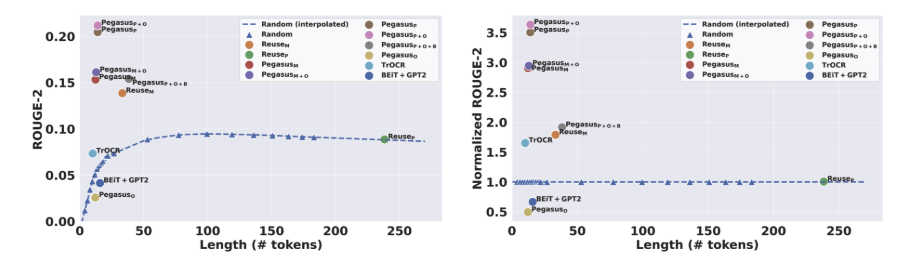
- 다양한 품질 빔에서의 자동 평가: 저품질 캡션의 영향을 검증하기 위해 도움 되는 빔과 도움 되지 않는 빔 세트에 대해 자동 평가를 다시 수행했습니다. 그림 3은 각 모델에 대한 도움 되는 빔과 도움 되지 않는 빔 세트의 정규화된 ROUGE-2 및 MoverScore 점수를 보여줍니다. 대부분의 모델은 도움 되지 않는 빔에서 더 나은 성능을 보였지만, PegasusP+O+B는 도움 되는 빔에서 더 나은 점수를 기록했습니다. PegasusP+O+B는 30개 이상의 토큰을 가진 캡션으로 훈련되었습니다. 이 결과는 더 긴 캡션만 사용하는 등 훈련 데이터 품질을 개선하면 모델의 성능에 긍정적인 영향을 미칠 수 있음을 시사합니다.
- 다양한 품질 빔에서의 인간 평가: 우리는 또한 도움 되는 빔과 도움 되지 않는 빔에 대해 인간 평가 점수를 다시 평가했습니다. 섹션 7.2의 인간 평가는 90개의 그림(도움 되는 빔 55개, 도움 되지 않는 빔 35개)만을 다루었습니다. 표 6은 결과를 보여줍니다. 평균적으로, PegasusP+O+B(1.867)는 도움 되지 않는 빔에서 저자가 작성한 캡션(2.019)보다 더 높은 평가를 받았으며, 이 경우 기계 생성 캡션이 인간 평가자들에 의해 35번 중 22번 선호되었습니다. 이 결과는 저자가 작성한 캡션이 크게 도움이 되지 않는 경우, 기계가 더 나은 캡션을 생성할 가능성이 있음을 시사합니다.
8.2 Challenge 2: What Constitutes a Good Figure Caption?

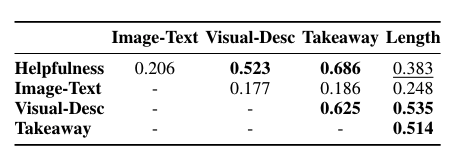
- 상관관계 분석: 우리는 네 가지 측면 간의 피어슨 상관관계를 계산했습니다(Rodgers and Nicewander, 1988). 결과는 표 7에 나와 있습니다. 가장 높은 상관관계는 핵심 메시지(Takeaway)와 도움 여부(Helpfulness) 간에 나타나, 고품질 캡션이 그림의 주요 메시지를 정확하게 포착한다는 것을 시사합니다.
- 주요 발견: 도움 여부, 시각적 설명(Visual-Description), 핵심 메시지 간에도 강한 상관관계가 있어, 좋은 캡션이 시각적 정보를 효과적으로 전달하고 주요 메시지를 요약함을 나타냅니다. 그러나 표 5에 따르면, 시각적 특성과 핵심 메시지를 설명한 캡션은 각각 16.04%와 18.55%에 불과했습니다. 도움 여부와 길이 간의 중간 정도의 상관관계는 더 긴 캡션이 독자에게 일반적으로 더 도움이 된다는 이전 연구 결과를 지지합니다(Hartley, 2003; Gelman et al., 2002).
8.3 Caption Length Distribution
- 캡션 길이 문제: 이 연구의 개발 과정에서 캡션 길이는 일관된 문제로 나타났습니다. 기존 문헌에서는 더 긴 캡션이 독자에게 유익하다고 제시하고 있지만(Hartley, 2003; Gelman et al., 2002), 공간 제약으로 인해 저자는 짧은 캡션을 작성할 수밖에 없는 경우가 많습니다.
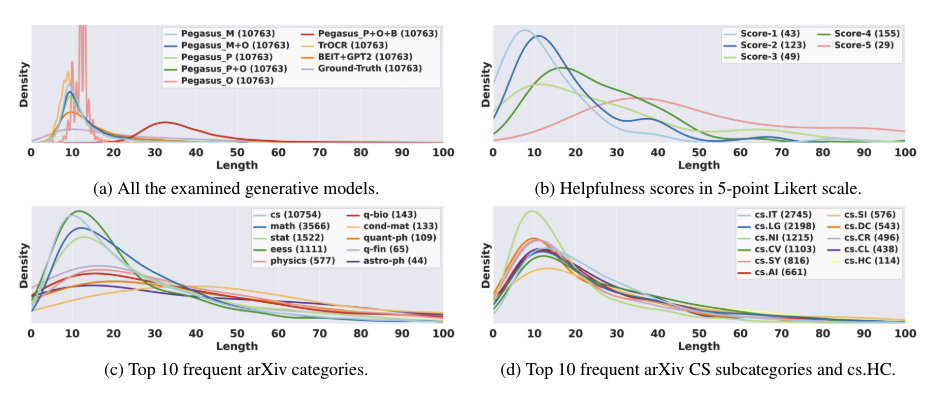
- 캡션 길이 분석: 저자가 작성한 캡션과 기계가 생성한 캡션의 길이를 분석하기 위해 커널 밀도 추정(KDE) 플롯을 사용했습니다. 그림 4a에 나타난 바와 같이, 대부분의 모델은 10 토큰에서 공통된 피크를 보이는 반면, PegasusP+O+B는 30 토큰 근처에서 유의미한 편차를 보였습니다. 그림 4b는 품질 주석 데이터(섹션 8.2 참조)에서 도출된 도움 여부 점수의 분포를 나타냅니다. 최대 도움 점수인 5를 받은 캡션은 35 토큰에서 피크를 보였으며, 높은 점수와 함께 캡션 길이의 명확한 변화가 나타났습니다. 그림 4c에서는 arXiv의 상위 10개 카테고리 분류를 조사했습니다. 이 그림은 cs, math, stat, eess 분야의 캡션이 더 짧은(10 토큰) 경향이 있는 반면, 나머지 카테고리(cond-mat, quant-ph, q-bio 등)는 더 긴 캡션의 확률이 높음을 시사합니다. 그러나 cs 도메인 내에서는(그림 4d), 상위 10개 하위 카테고리 간에 캡션 길이 분포에 대한 유의미한 차이는 나타나지 않았습니다.
9. Discussion
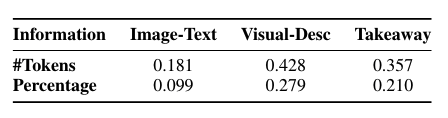
- 텍스트만으로 충분한가?: 우리의 결과는 그림을 언급하는 문단을 요약하는 것만으로도 캡션을 생성하기에 충분함을 보여줍니다. 표 2에서 PegasusP와 PegasusP+O의 유사한 점수가 이를 증명합니다. OCR을 추가하는 것은 제한된 영향을 미쳤습니다. Yang et al.(2023)의 최근 연구에서도, 최고의 성능을 보인 모델은 그림을 언급하는 문단과 OCR 토큰만 고려했으며, 그림의 이미지는 고려하지 않았습니다. 이 결과는 우리가 시각적 정보가 정말로 필요한지에 대한 흥미로운 질문을 제기합니다. 토큰 정렬 연구(섹션 5)는 캡션 정보의 75.19%가 문단에서 찾을 수 있음을 보여주며, 24.81%의 정보가 누락되어 있음을 의미합니다. 이 누락된 정보를 이해하는 것이 모델 성능을 향상시키는 데 도움이 될 수 있습니다. 따라서 우리는 누락된 정보의 양과 품질 주석 데이터(섹션 8.2)의 세 가지 측면 평점(이미지-텍스트, 시각적 설명, 핵심 메시지) 간의 상관관계를 계산했습니다. 표 8은 누락된 정보의 정도와 시각적 설명 및 핵심 메시지 간의 긍정적인 상관관계를 보여줍니다. 이는 시각적 설명을 포함하는 것이 성능 향상에 중요한 역할을 할 수 있음을 시사합니다. 또한, 표 5에서 도움 여부와 시각적 설명 간의 강한 상관관계는 좋은 캡션을 작성하는 데 이미지 정보가 필요함을 나타냅니다. OCR은 이미지 텍스트(예: 라벨, 범례)만을 캡처할 수 있으며 시각적 요소 정보(예: "점선")는 캡처할 수 없습니다. 미래에는 이미지와 텍스트를 효과적으로 통합할 수 있는 다중 모드 모델을 개발하는 것이 유망한 방향이 될 것입니다.
- 캡션의 최적 길이는 무엇인가?: 우리의 연구는 더 짧은 캡션을 필터링하는 것이 더 도움이 되는 캡션을 생성하는 데 도움이 될 수 있음을 나타냅니다. 그러나 결과 캡션은 일반적으로 더 길어지며, 이는 그림 4a에서 PegasusP+O+B의 오른쪽으로의 이동으로 나타납니다. 이는 더 긴 캡션이 본질적으로 더 많은 정보를 포함하고 있기 때문에 유용성에 있어 짧은 캡션과 비교하는 것이 공정한가라는 질문을 제기합니다. 우리의 자동 평가는 길이 정규화를 통해 이를 해결했지만, 인간 평가와 품질 주석에서는 주석자들에게 캡션 길이를 고려하도록 명시적으로 지시하지 않았습니다. 그럼에도 불구하고, 주석자들에게 도움이 되는 캡션을 식별할 때 캡션 길이를 고려하도록 요청하더라도, "이상적인" 캡션 길이는 여러 요인으로 인해 주석자마다 다를 수 있습니다. 예를 들어, 그림 4c에서 보이는 바와 같이, 도메인에 따라 캡션 길이 분포가 다릅니다. 인간 평가의 낮은 상호 동의도(섹션 7.2 참조)는 또한 개인의 선호도가 이상적인 캡션 길이에 영향을 미칠 수 있음을 시사합니다. 또한, 이상적인 길이는 상황에 따라 달라질 수 있습니다: 작성자는 페이지 제약으로 인해 더 짧은 캡션을 선호할 수 있지만, 독자는 더 길고 정보가 많은 캡션을 선호할 수 있습니다(Stokes and Hearst, 2022; Sun et al., 2019). 이 문제를 해결하기 위해, 모델이 다양한 길이의 캡션을 생성하여 다른 사용자와 상황에 맞출 수 있도록 하는 것이 잠재적인 미래 방향이 될 수 있습니다.
10. Conclusion and Future Work
- 새로운 관점 제시: 이 연구는 자동 그림 캡션 생성에 대한 새로운 관점을 제시하여, 그림을 언급하는 문단을 요약하는 언어 기반 접근 방식이 기존의 비전 기반 방법보다 뛰어날 수 있음을 입증했습니다. 우리의 분석은 arXiv 논문에서 많은 도움이 되지 않는 캡션을 보여주며, 데이터 품질이 캡션 성능에 미치는 영향을 강조했습니다. 이 연구는 데이터 선택, 수정 및 증강 전략 탐구, 새로운 평가 방법 개발, 노이즈 데이터를 더 잘 처리하는 강력한 모델 생성 등 향후 연구의 기초를 마련합니다. 또한 다양한 그림과 기사 유형을 다루는 기술의 범위를 확장하는 것을 목표로 합니다.
- 감사의 말: 익명의 리뷰어들에게 건설적인 피드백에 감사드립니다. 이 연구는 Adobe의 기금과 펜실베니아 주립대학교 정보과학기술대학(IST)의 시드 펀드의 지원을 받았습니다.
- 한계점: 제안된 방법이 효과적임을 입증했지만, 몇 가지 한계가 있습니다. 첫째, 캡션을 생성하려면 언급이 필요하지만, 실제 데이터에서 주어진 그림에 대한 언급을 자동으로 식별하는 것은 항상 쉬운 일이 아닙니다. 원래 SCICAP의 그림 중 18.81%는 언급이 확인되지 않아 이 연구에서 제외했습니다. 이러한 차이는 이미지 추출 또는 이미지 유형 분류(예: 표)와 같은 상위 컴포넌트에서 발생한 오류, 예상치 못한 그림 인덱스 형식(예: "Figure VIII", "Figure C·1", "Fig.Fig. 4(b)"), PDF 파싱 오류 또는 논문에서 그림이 언급되지 않은 경우 등 여러 요인에 기인합니다. 둘째, 우리의 방법은 이미지를 대신하여 텍스트를 주요 정보 소스로 사용하므로, 자연스럽게 텍스트의 모든 제약을 상속합니다. 텍스트에서 언급하지 않은 시각적 요소를 캡처할 수 없으며, 텍스트가 잘 작성되지 않은 경우 어려움을 겪습니다. 마지막으로, 이 논문은 arXiv 논문의 비합성 선형 차트에 초점을 맞췄으며, 인간 평가는 NLP 논문에만 초점을 맞췄습니다. 일반화 가능성을 조사하기 위해 더 많은 연구가 필요합니다.
- 윤리 성명서: 제안된 기술이 독자에게 거의 위험을 초래하지 않는다고 생각합니다. 이는 논문에 이미 제시된 내용을 요약하기 때문입니다. 그러나 생성된 캡션에 부정확한 정보가 포함된 경우 독자를 오도할 수 있습니다. 또한, 제안된 기술은 시각적 콘텐츠를 무시하는 특성이 있어 그림 캡션의 접근성에 영향을 미칠 수 있습니다.
A. Token Overlap Study
- 추가 연구 개요: 섹션 5를 뒷받침하기 위해 추가 연구를 수행했습니다. 우리는 다양한 설정에서 추출된 언급과 캡션에 대한 n-그램 정밀도 점수(BLEU-4)를 계산했습니다.
- 언급(Mentions):
- 첫 번째 언급(First Mention): 논문에서 그림을 처음 언급하는 문장.
- 임의의 언급(Random Mention): 모든 언급 중 임의로 선택한 문장.
- 임의의 문장(Random Sentence): 논문에서 임의로 선택한 문장.
- 추가로, 그림과 관련된 정보가 포함될 수 있는 주변 문맥을 고려하여 한두 개의 다음 문장도 포함했습니다.
- 캡션(Captions):
- 첫 번째 캡션(First Caption): 캡션의 첫 번째 문장.
- 전체 캡션(Whole Caption): 캡션의 모든 문장.
- 결과 요약:
- 임의의 문장(Random Sentence) 기준의 매우 낮은 BLEU-4 점수(First: 0.01, Whole: 0.01)는 임의로 선택된 문장이 캡션과 관련된 정보가 매우 제한적임을 나타냅니다.
- 반면, 첫 번째 언급(First Mention)과 임의의 언급(Random Mention)의 결과(First: 9.39, Whole: 10.54 및 First: 9.15, Whole: 10.28)는 캡션과 관련된 정보가 훨씬 더 많이 포함되어 있음을 보여줍니다.
- 첫 번째 언급의 모든 점수가 임의의 언급보다 약간 더 높은데, 이는 저자가 처음 그림을 소개할 때 더 많은 세부 정보를 제공하는 경향이 있음을 시사합니다.
B. Data Preprocessing Details
- 데이터 전처리 단계: 섹션 4의 보충 자료로 자세한 데이터 전처리 단계를 설명합니다.
- 데이터셋 재분할:
- SCICAP은 원래 비전-투-언어 작업을 위해 생성되었으며, 우리는 우리의 작업을 위해 새로운 학습/검증/테스트 분할이 필요했습니다.
- 동일 논문 내의 다른 그림은 SCICAP의 다른 데이터 분할에 할당될 수 있지만, 논문의 텍스트는 더 쉽게 겹칠 수 있어 텍스트 요약 작업에 문제가 될 수 있습니다.
- 우리는 SCICAP을 재분할하여 동일한 논문의 그림이 다른 데이터 분할에 속하지 않도록 했으며, 언급이 확인되지 않은 그림은 제외했습니다.
- 결과적으로, 이 작업에 사용된 [train/val/test] 세트는 각각 [86,825/10,833/10,763]개의 그림이 [48,603/6,055/6,053]개의 논문에서 소싱되었습니다.
- OCR:
- OCR 텍스트는 EasyOCR(JaidedAI, 2022)을 사용하여 모든 그림에서 추출되었습니다.
- EasyOCR의 출력에는 OCR 텍스트와 해당 경계 상자가 포함되었습니다.
- OCR 텍스트를 모델에 통합하기 위해, 우리는 경계 상자를 왼쪽에서 오른쪽으로, 위에서 아래로 순회하여 얻은 좌표 시퀀스와 OCR 텍스트를 연결했습니다.
- 대표성:
- 우리는 수동으로 399개의 그림을 검증했으며(섹션 8에서 사용된 세트), 81.2%(324/399)가 학술회의에 발표되었고, 51.9%(207/399)가 ACL Anthology, IEEE 또는 ACM에서 발표되었음을 확인했습니다. 이는 데이터가 대표성을 가진다는 것을 시사합니다.
C. Training and Decoding Details
모델 훈련 세부 사항 및 디코딩 구성:
- 텍스트 요약 모델 훈련 세부 사항:
- Pegasus5를 HuggingFace 구현(Wolf et al., 2020)을 사용하여 텍스트 요약 작업에 맞게 미세 조정했습니다.
- 모든 모델은 최대 텍스트 길이를 제외한 동일한 훈련 하이퍼파라미터를 공유했습니다. 데이터는 모든 설정에서 다르기 때문에 최대 소스 길이와 타겟 길이는 (i) 텍스트의 95% 이상을 잘리지 않도록 하고, (ii) 머신에 맞도록 설정했습니다. 길이 구성은 표 9에 나와 있습니다.
- 다른 하이퍼파라미터: 배치 크기 = 32, 학습률 = 5e-5 (선형 감쇠 스케줄러 사용), 훈련 에포크 수 = 200.
- 모델은 5 에포크마다 평가되었고, ROUGE-2 점수가 가장 높은 모델이 테스트에 사용되었습니다(Liu and Liu, 2021; Zhong et al., 2020; Xu et al., 2020).
- 모든 모델은 NVIDIA A100 GPU를 사용하여 훈련되었으며, 각 모델의 훈련에는 1~3일이 소요되었습니다.
- 비전-투-언어 모델 훈련 세부 사항:
- HuggingFace를 사용하여 두 개의 비전-투-언어 모델을 미세 조정했습니다: (i) BEiT6과 GPT-27을 사용하는 시퀀스-투-시퀀스 모델과 (ii) TrOCR.8
- 훈련에 사용된 하이퍼파라미터: 최대 타겟 길이 = 100, 학습률 = 2e-5 (선형 웜업: 한 에포크) 및 선형 감쇠 스케줄러.
- 배치 크기는 각각 32와 64였으며, AdamW(Loshchilov and Hutter, 2019)를 사용하여 훈련되었고, 가중치 감쇠 = 1e-4로 100 에포크 동안 훈련되었습니다.
- 모델은 매 에포크마다 평가되었고, ROUGE-2 점수가 가장 높은 모델이 테스트에 사용되었습니다(Liu and Liu, 2021; Zhong et al., 2020; Xu et al., 2020).
- 모델은 NVIDIA A100 GPU를 사용하여 2일 동안 훈련되었습니다.
- 디코딩:
- 모든 생성 모델의 캡션은 빔 샘플링 전략을 사용하여 디코딩되었습니다. 빔 크기 = 5, 온도 = 0.8, top-k = 100, 반복 페널티 = 3.0, 최소 길이 = 10, 최대 길이 = 100.
D. Interfaces
- 그림 5:
- 섹션 7.2를 참고하면, 인간 평가자가 캡션을 순위 매길 때 사용한 인터페이스를 보여줍니다.
- 논문의 제목(논문 URL로의 링크 없이)과 초록이 표시됩니다.
- 인간 평가자는 왼쪽 창에 표시된 캡션(각각 그림과 함께 표시)을 드래그하여 오른쪽 창에 드롭하여 순위를 매깁니다.
- 캡션의 초기 표시 순서는 인터페이스에서 무작위로 설정됩니다.
- 저자가 작성한 캡션에 대한 편향을 방지하기 위해 논문의 PDF나 논문 URL로의 링크는 표시하지 않았습니다.
- 그림 6:
- 섹션 8.2를 참고하면, 캡션의 유용성을 평가할 때 사용한 인터페이스를 보여줍니다.
- 논문의 제목(논문 URL로의 하이퍼링크 포함), 초록, 논문 PDF 파일이 표시되며, 대상 그림의 이미지/캡션과 모든 질문이 함께 표시됩니다.
- 평가자가 캡션의 품질에 대해 더 잘 판단할 수 있도록 논문의 PDF를 표시했습니다.
- 사용된 모델:
- microsoft/beit-large-patch16-384
- gpt2-large
- microsoft/trocr-large-printed
E. Additional Experimental Results
- 정규화 점수:
- 그림 8부터 11은 생성된 텍스트 길이와 성능(ROUGE-1, ROUGE-L, MoverScore, BERTScore) 간의 관계를 보여줍니다.
- 랜덤 라인은 텍스트 길이와 성능이 독립적이지 않음을 나타내어, 텍스트 길이에 따른 정규화가 필요함을 시사합니다.
- 표 11은 표 2에서 사용된 각 메트릭에 대한 해당 랜덤 점수를 보여줍니다.
- 예제:
- 그림 7은 생성 출력의 두 샘플을 보여줍니다.
- PegasusP+O+B가 생성한 정보는 유용할 수 있지만(A), 사실 오류를 도입할 수도 있습니다(B).
- 다양한 품질 빔에서의 성능:
- 그림 12는 다양한 품질 빔에서의 ROUGE-1 및 ROUGE-L 변화를 보여줍니다.
- 섹션 8.1에서와 유사한 결과를 볼 수 있으며, 다양한 생성 모델 중 데이터 품질 관리를 통해 훈련된 모델(PegasusP+O+B)만이 도움 되는 빔에서 더 나은 성능을 보여주어, 도움이 되는 캡션과 더 유사한 캡션을 생성했습니다.
'논문 > Natural Language Processing (NLP)' 카테고리의 다른 글
| Orca: Progressive Learning from ComplexExplanation Traces of GPT-4 (정리중) (0) | 2023.09.19 |
|---|
