728x90
반응형
SMALL

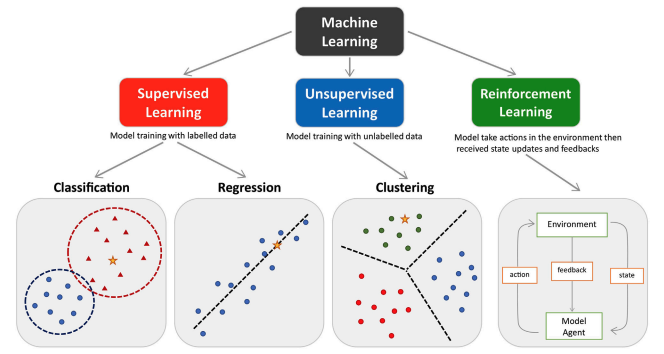
Machine Learning (기계학습)
- 컴퓨터 스스로 대용량 데이터에서 지식이나 패턴을 찾아 학습하고 예측을 수행하는 것
- 컴퓨터가 학습할 수 있게 하는 알고리즘과 기술을 개발하는 분야
- train 데이터를 머신러닝을 적용해서 학습시키고, 이 학습 결과로 모형이 생성됨
| 구분 | 유형 | 알고리즘 |
| 지도 학습 (supervised learning) |
분류(classification) | - K-최근법 이웃 (K-Nearest Nighbor, KNN) - 서포트 벡터 머신 (Support Vector Machine, SVM) - 결정 트리 (decision tree) - 로지스틱 회귀 (logistic regression) |
| 회귀(regression) | - 선형 회귀 (linear regression) |
|
| 비지도 학습 (unsupervised learning) |
군집(clustering) | - K-평균 군집화 (K-means clustering) - 밀도 기반 군집 분석 (DBSCAN) |
| 차원 축소(dimensionality reduction) | - 주성분 분석 (Principal Component Analysis, PCA) |
|
| 강화 학습 (reinforcement learning) |
- | - 마르코프 결정 과정 (Markov Decision Process, MDP) |
지도 학습 (Supervised Learning):
- 분류 (Classification):
- K-최근접 이웃 (K-Nearest Neighbor, KNN): 새로운 데이터를 주변의 데이터 포인트와 비교하여 가장 가까운 이웃들의 다수결로 분류하는 알고리즘입니다.
- 서포트 벡터 머신 (Support Vector Machine, SVM): 데이터 포인트를 분리하는 결정 경계를 찾아내고, 클래스 간의 간격(margin)을 최대화하는 방식으로 분류하는 알고리즘입니다.
- 결정 트리 (Decision Tree): 트리 구조로 데이터를 분할하여 분류하는 방법으로, 각 분할 지점에서 특성(feature)을 기준으로 가장 중요한 특성을 선택합니다.
- 로지스틱 회귀 (Logistic Regression): 이진 분류나 다중 분류에 사용되는 통계 기반의 회귀 알고리즘으로, 로지스틱 함수를 사용하여 확률을 예측합니다.
- 회귀 (Regression):
- 선형 회귀 (Linear Regression): 입력 특성과 가중치 사이의 선형 관계를 사용하여 연속적인 숫자 값을 예측하는 회귀 알고리즘입니다.
비지도 학습 (Unsupervised Learning):
- 군집 (Clustering):
- K-평균 군집화 (K-Means Clustering): 데이터를 K개의 그룹 또는 군집으로 분할하는 알고리즘으로, 각 데이터 포인트를 가장 가까운 중심에 할당합니다.
- 밀도 기반 군집 분석 (DBSCAN): 데이터의 밀도를 기반으로 군집을 찾는 알고리즘으로, 덴드로그램을 사용하여 클러스터를 생성합니다.
- 차원 축소 (Dimensionality Reduction):
- 주성분 분석 (Principal Component Analysis, PCA): 데이터의 차원을 줄이는 방법으로, 상관 관계가 있는 변수를 결합하여 주성분을 생성하여 데이터를 설명하는 데 사용됩니다.
강화 학습 (Reinforcement Learning):
- 마르코프 결정 과정 (Markov Decision Process, MDP): 에이전트가 환경과 상호 작용하며 보상을 최대화하는 최적의 정책(policy)을 학습하는 알고리즘입니다. 에이전트는 어떤 상태에서 어떤 행동을 취해야 하는지를 학습하며, 게임 및 로봇 제어 등 다양한 응용 분야에서 사용됩니다.
Machine Learning Base Pipeline
: Data Collect, Preprocessing, Training, Service
- Data Collect (데이터 수집)
데이터 수집은 머신 러닝 프로젝트의 시작 단계로, 모델을 훈련시키기 위한 데이터를 수집하는 과정을 나타냅니다. 이 데이터는 문제의 성격에 따라 다양할 수 있으며, 예를 들어 텍스트, 이미지, 오디오 등의 다양한 형태일 수 있습니다. - Preprocessing (전처리)
데이터 수집 후, 데이터를 클렌징하고 준비하는 과정으로, 누락된 값, 이상치, 중복 데이터 등을 처리합니다. 또한 데이터를 모델이 학습할 수 있는 형태로 변환하는 작업도 이 단계에서 수행됩니다.
- Feature Engineering
피처 엔지니어링은 모델에 입력으로 제공될 특성(feature)을 생성하거나 변환하는 과정을 의미합니다. 이 단계에서는 도메인 지식을 활용하여 새로운 특성을 만들거나 기존 특성을 가공하여 모델의 성능을 향상시킵니다.- Feature Extraction
피처 추출은 주어진 데이터에서 주요 정보를 추출하여 모델 학습에 사용할 수 있는 형태로 만드는 프로세스입니다. 주로 차원 감소 기법이 사용되며, 예를 들어 주성분 분석 (PCA)이나 특성 추출을 위한 신경망과 같은 기술을 적용할 수 있습니다. - Feature Selection
피처 선택은 모델 학습에 사용할 특성 중 가장 중요한 특성을 선택하는 작업을 말합니다. 불필요한 특성을 제거하거나 가장 중요한 특성만을 선택함으로써 모델의 복잡성을 줄일 수 있습니다.
- Feature Extraction
- Data Split (Train / Test)
데이터를 학습용(train)과 테스트용(test)으로 나누는 것은 모델의 성능을 평가하기 위한 중요한 단계입니다. 일반적으로 데이터의 일부는 모델 훈련에 사용되고 나머지 일부는 모델 성능을 검증하고 평가하는 데 사용됩니다.
- Feature Engineering
- Training
모델 훈련은 주어진 데이터를 사용하여 모델을 학습시키는 단계입니다. 이 과정에서 모델은 데이터의 패턴과 관계를 학습하고 최적의 파라미터를 조정합니다.- Build & Train Model
모델 아키텍처를 선택하고 구축한 다음 학습 데이터를 사용하여 모델을 훈련시키는 단계입니다. 이것은 모델의 가중치 및 매개변수를 조정하고 목표에 맞게 모델을 최적화하는 과정입니다. - Model Validation
모델의 성능을 평가하고 검증하는 단계로, 테스트 데이터를 사용하여 모델의 정확성, 정밀도, 재현율 등의 성능 지표를 평가합니다. 이를 통해 모델의 일반화 능력을 판단할 수 있습니다.
- Build & Train Model
- Service
모델을 실제 환경에서 서비스할 수 있도록 배포하고 운영하는 단계입니다. 이 단계에서는 모델이 실제 데이터에 대한 예측을 수행하고 필요한 경우 모델을 유지 보수하며 계속해서 개선할 수 있습니다.
728x90
반응형
LIST
'Python > ML' 카테고리의 다른 글
| (KNN) K-Nearest Neighbors 정리 (0) | 2023.01.18 |
|---|
