1. 글을 작성하게 된 계기
Kubernetes(K8s) 환경에서 GPU 노드를 설정하고 연결하는 과정이 복잡하여, 이를 문서로 정리하려 합니다.
가정:
- kubectl과 helm은 이미 설치되어 있음.
- GPU 서버에서 nvidia-smi 명령어가 정상적으로 작동함.
kubectl 설치 방법
최신 kubernetes(쿠버네티스) 설치 방법 (feat. Ubuntu)
1. 글을 작성하게 된 계기 K8s (1.27.x )를 구축하고자 하는데 최근에 업데이트 된 내용에 대한 글이 없어 정리하고자 합니다.매일 까먹는 나를 위해서 그리고 어려움을 겪고 있는 다른 분들에게조
jongsky.tistory.com
helm 설치 방법
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 \
&& chmod 700 get_helm.sh \
&& ./get_helm.sh
2. 설치 및 연결 방법
1. Namespace 생성 및 연결
kubectl create ns gpu-operator
kubectl label --overwrite ns gpu-operator pod-security.kubernetes.io/enforce=privileged
kubectl get ns --show-labels | grep gpu- 설명: GPU Operator 전용 네임스페이스(gpu-operator)를 생성하고, pod 보안 정책을 'privileged'로 설정하여 GPU 접근을 허용합니다.
2. GPU Operator 설치 준비
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo update- 설명: NVIDIA의 Helm Chart 저장소를 추가하고 업데이트합니다.
3. Helm 차트 다운로드 및 설정
mkdir temp-helm && cd temp-helm
helm pull nvidia/gpu-operator --untar
cd gpu-operator- 설명: Helm 차트를 다운로드한 후, 작업 디렉토리를 생성하여 GPU Operator의 설정 파일을 준비합니다.
4. 노드에 Taint 적용
kubectl taint node gpu-worker-node nvidia.com/gpu=true:NoSchedule- 설명: 특정 노드에 GPU 관련 taint를 적용하여, GPU가 있는 노드에 특정 파드만 스케줄링되도록 제한합니다.
5. values.yaml 설정
vi values.yaml- 설명: Helm 차트의 환경설정 파일(values.yaml)을 수정하여 GPU Operator를 설치할 때 필요한 설정을 변경합니다.
6. 설정 내용 (driver, toolkit, migManager 등)
- driver 및 각종 설정 변경
# 이미 설치되어 있기 때문에 false로 수정
driver:
enabled: false
# 그래픽카드가 a100, h100 등만 사용가능
migManager:
enabled: false
vgpuDeviceManager:
enabled: false
vfioManager:
enabled: false- toolkit 설정
- 설명: containerd를 사용하므로 해당 설정을 활성화하여 GPU 컨테이너 툴킷을 설정합니다.
toolkit:
enabled: true
repository: nvcr.io/nvidia/k8s
image: container-toolkit
version: v1.16.2-ubuntu20.04
env:
- name: CONTAINERD_CONFIG
value: /etc/containerd/config.toml
- name: CONTAINERD_SOCKET
value: /run/containerd/containerd.sock
- name: CONTAINERD_RUNTIME_CLASS
value: nvidia
- name: CONTAINERD_SET_AS_DEFAULT
value: "true"- taint 설정
- 설명: GPU 노드에만 파드가 스케줄링되지 않도록 설정하여 관리 효율성을 높입니다.
- key: "nvidia.com/gpu"
operator: "Equal"
value: "present"
effect: "NoSchedule"
이전 설정 (operator: Exists)
- 기존 설정은 operator: Exists로, nvidia.com/gpu 키만 존재하면 그 노드에 해당 taint가 적용됩니다. 즉, 이 설정은 GPU가 있는 노드에는 어떤 파드도 스케줄링되지 않도록 설정하는 것입니다(단, 이 taint와 일치하는 toleration을 가진 파드는 예외). 즉, nvidia.com/gpu라는 키가 노드에 있으면 해당 노드로 파드가 스케줄링되지 않도록 제한을 두고 있습니다.
변경된 설정 (operator: Equal)
- 변경된 설정은 operator: Equal로 바뀌었고, value: "present"라는 값이 추가되었습니다. 이제 이 taint는 노드의 nvidia.com/gpu 키의 값이 "present"인 경우에만 적용됩니다. 이 조건이 맞으면 이 노드에 파드가 스케줄링되지 않도록 설정됩니다.
차이점
- 이전 설정: 노드의 nvidia.com/gpu라는 키가 존재하기만 하면 해당 노드는 스케줄링이 제한됩니다. 값은 상관하지 않으며, 키 자체가 존재하는지 여부만 따졌습니다.
- 변경된 설정: nvidia.com/gpu 키가 존재하는 것뿐만 아니라 그 값이 "present"일 때만 스케줄링이 제한됩니다. 따라서, nvidia.com/gpu 키가 있지만 그 값이 "present"가 아니면 해당 노드에 스케줄링 제한이 적용되지 않습니다.
변경의 효과
이 설정의 변경은 좀 더 세밀한 제어를 가능하게 합니다. 이제 nvidia.com/gpu 키가 존재할 뿐만 아니라 그 값이 "present"일 경우에만 스케줄링이 제한됩니다. 이 말은 GPU가 있는 노드에서도 nvidia.com/gpu 키가 present로 설정된 노드에만 스케줄링 제한을 적용할 수 있다는 의미입니다. 즉, 모든 GPU 노드가 아니라 특정 조건을 만족하는 GPU 노드에만 스케줄링 제한을 걸 수 있게 됩니다.
따라서, nvidia.com/gpu=present라는 조건을 가진 노드에만 파드가 스케줄링되지 않도록 하고자 할 때 유용한 설정 변경입니다.
7. Helm을 통한 GPU Operator 설치
helm install gpu-operator nvidia/gpu-operator -n gpu-operator --create-namespace -f ~/workspace/reboott/AUW/k8s_test/temp-helm/gpu-operator/values.yaml
## 참고 (삭제 명령어)
helm uninstall gpu-operator -n gpu-operator- 설명: Helm 차트의 values.yaml 파일을 사용하여 GPU Operator를 설치합니다.

8. 설치 확인
kubectl get all -n gpu-operator
or
kubectl get all -n gpu-operator -o wide- 설명: GPU Operator가 정상적으로 설치되었는지 확인합니다.
9. 노드의 GPU 상태 확인
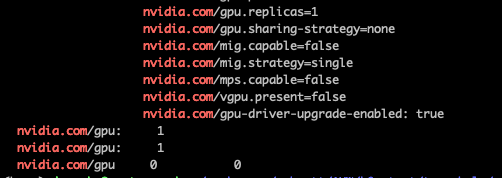
kubectl describe no | grep nvidia.com- 설명: 노드의 GPU 관련 설정(nvidia.com/gpu)이 제대로 반영되었는지 확인합니다.
3. 참고
Installing the NVIDIA GPU Operator — NVIDIA GPU Operator 24.6.2 documentation
When set to true, the Operator installs two additional runtime classes, nvidia-cdi and nvidia-legacy, and enables the use of the Container Device Interface (CDI) for making GPUs accessible to containers. Using CDI aligns the Operator with the recent effort
docs.nvidia.com
'Come on IT > DevOps' 카테고리의 다른 글
| Prometheus 및 Grafana 설치 (feat. 쿠베네티스) (1) | 2024.10.07 |
|---|---|
| worker node에서 명령어 실행이 안될 때 해결방법 (0) | 2024.10.06 |
| Kubernetes kubeadm init 오류 및 해결 방법 (0) | 2024.10.02 |
| 쿠버네티스(K8s) 명령어 정리 (1) | 2024.10.01 |
| K8s CrashLoopBackOff 해결 방법 (0) | 2024.09.30 |



